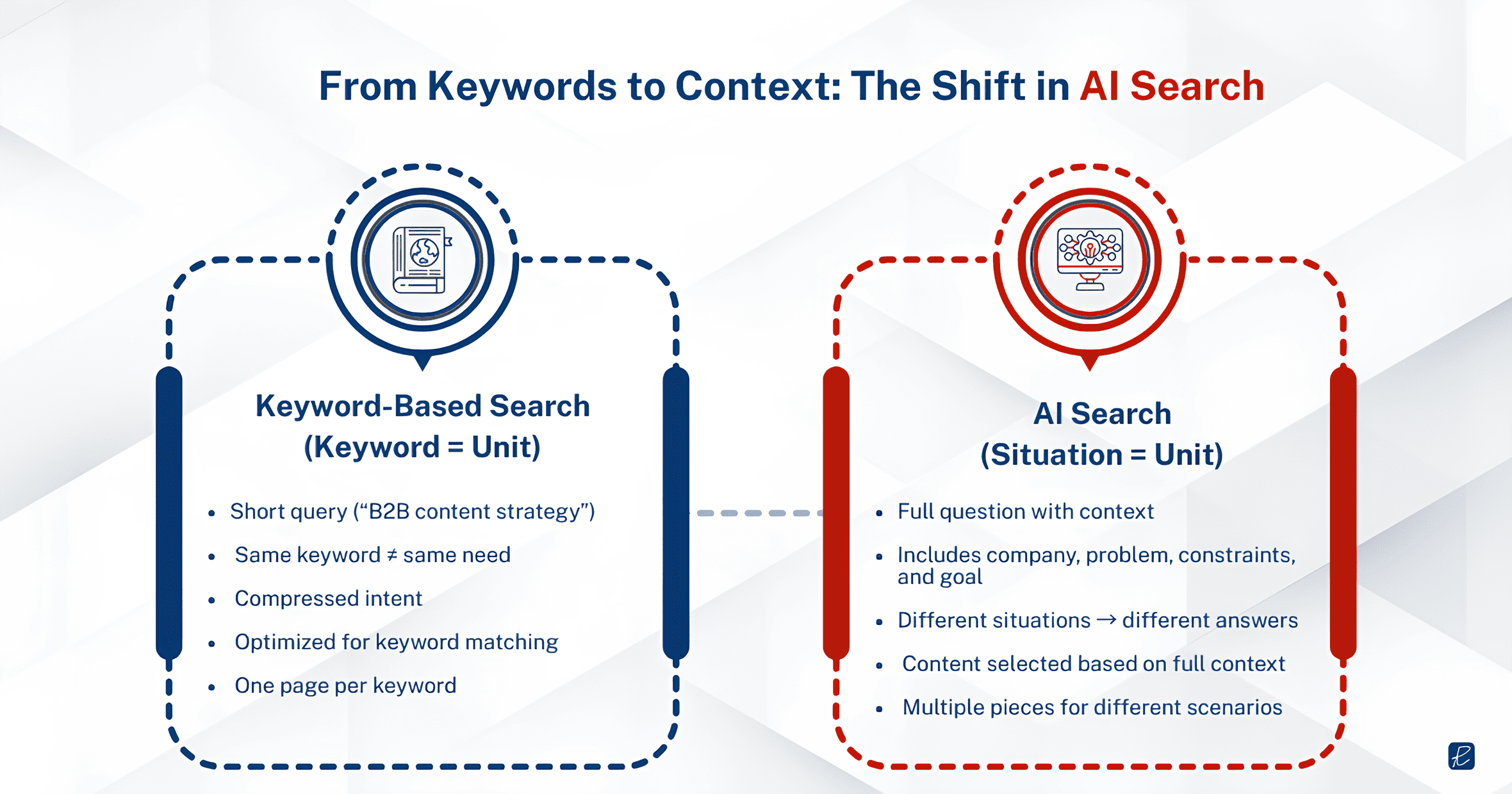
Keywords Are Fragments. AI Search Processes Full Situations.
A keyword is a compression artifact. When a VP of Marketing at a 200-person fintech company types “B2B content strategy” into Google, that phrase is a lossy summary of a much richer need. Maybe they are trying to figure out how to build pipeline through organic content because paid acquisition costs have doubled. Maybe they just lost their content lead and need to evaluate agency partners. Maybe they are preparing a board presentation on marketing efficiency. The keyword is identical in all three cases. The actual need is completely different.
Traditional SEO treats that keyword as the unit of work. You research its volume, assess its difficulty, publish content targeting it, and measure whether and where you rank. The entire workflow assumes that capturing the keyword captures the buyer.
AI search breaks this assumption because buyers no longer compress their questions into fragments. When the same VP opens ChatGPT or Perplexity, they type something closer to what they actually need: “We’re a Series B fintech, 200 people, our CAC on paid is getting unsustainable. What content strategy would help us build inbound pipeline from mid-market CFOs?” That prompt carries context that no keyword can. It includes their company stage, company size, the specific problem (CAC pressure), the target buyer (mid-market CFOs), and the goal (inbound pipeline). The LLM processes all of it, and the content it pulls into its answer is the content that addresses that full situation, not just the content that mentions “B2B content strategy” in the right density.
This is why content must be contextually relevant, not just keyword-matched.
The mechanism behind this is retrieval-augmented generation (RAG). When a buyer submits a prompt, the AI search engine does not just match it against a single index the way Google does. It breaks the query into sub-queries, searches across multiple sources for contextually relevant content, and synthesizes the results into a single response. Industry observers call this “query fan-out”: the model expands beyond the initial prompt to pull in related context, which means your content does not just need to match the buyer’s exact words. It needs to sit within a topic cluster that the retrieval system considers relevant to the broader situation the buyer described.
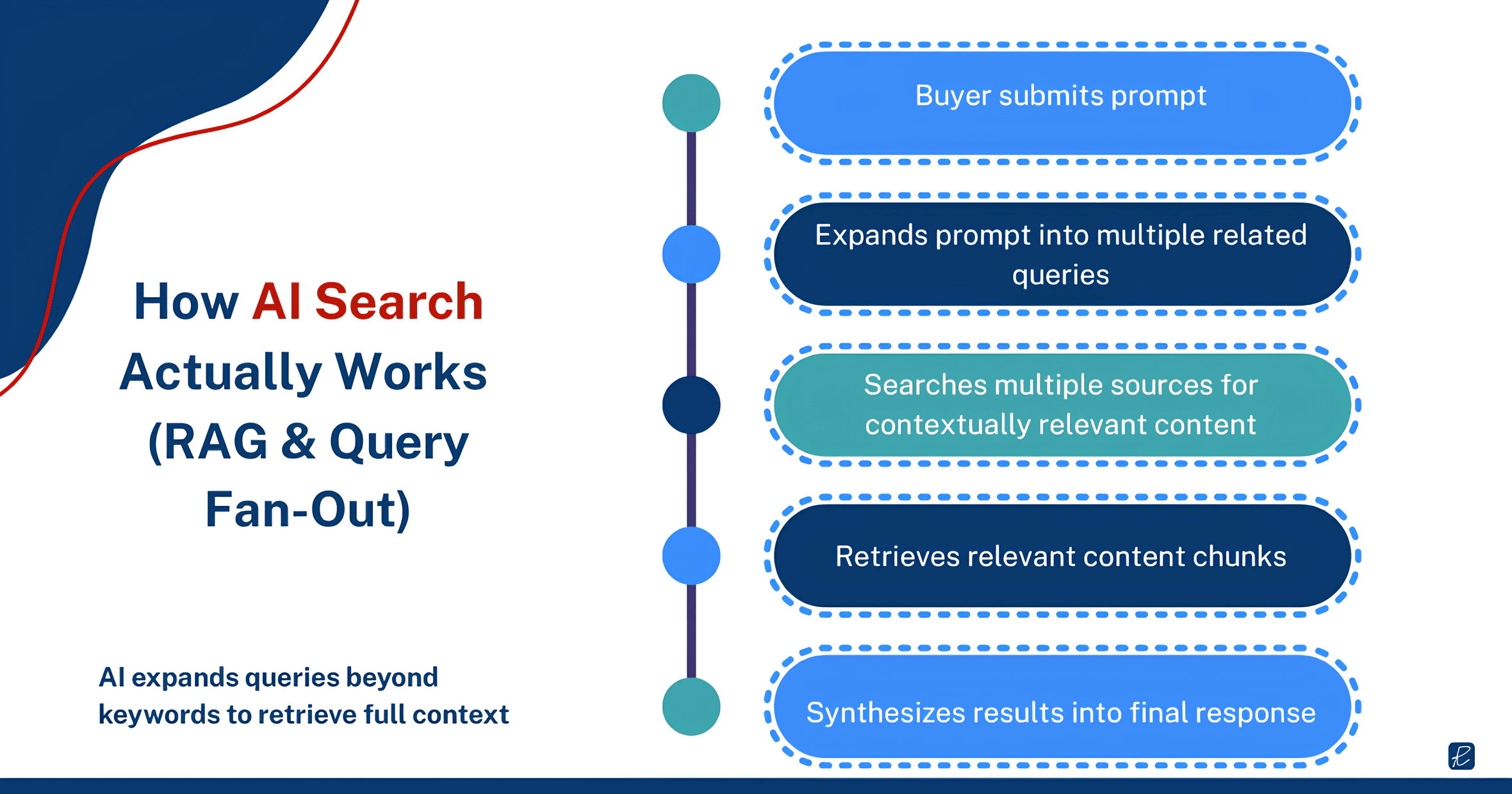
This changes what gets cited and what gets ignored.
What a keyword strategy misses
Consider a practical example. A B2B SaaS company selling marketing analytics software has a blog post ranking on page one for “marketing attribution models.” The post defines four types of attribution, explains how each works, and includes a comparison table. By keyword SEO standards, it is doing its job.
But when a buyer asks an AI assistant “How should a mid-market e-commerce company with a $500K annual ad budget think about marketing attribution?”, the LLM is not simply looking for pages that contain the phrase “marketing attribution models.” It is looking for content that addresses attribution in the context of e-commerce, at a mid-market scale, with budget constraints in a specific range.
The page-one-ranking article that defines four models generically may not appear in the AI response at all. A less prominent article from a smaller competitor that specifically discusses attribution for e-commerce companies with limited budgets gets cited instead.
We see this pattern consistently in AI visibility audits across our B2B client work: pages that rank well on Google for broad informational keywords are frequently absent from LLM responses to the same topic when the buyer adds situational detail to their prompt.
Ranking for a keyword and being the answer to a contextual question are two different achievements, and the gap between them is widening.
When keyword logic still holds
This does not mean keywords are irrelevant. They remain the backbone of how Google’s traditional index works, and Google still drives the majority of B2B search traffic. Keyword research still tells you what language your buyers use and what topics they care about.
The mistake is treating keyword coverage as sufficient for AI search visibility, or assuming that a page ranking well on Google will automatically perform well in LLM-generated results. These are increasingly separate distribution channels with different selection criteria, and content planning needs to account for both.
If any of the terminology here is unfamiliar, our GEO and AI search glossary covers concepts associated with AI visibility.
Your SEO Strategy Doesn’t Need Replacing. It Needs a Different Starting Point
Instead of starting with keyword lists, start with buyer scenarios and map keywords onto those scenarios.
This is the same shift we implement in AI Visibility Optimization programs, where content planning begins with buyer context rather than keyword volume.
Everything else in SEO still applies. What changes is the organizing principle.
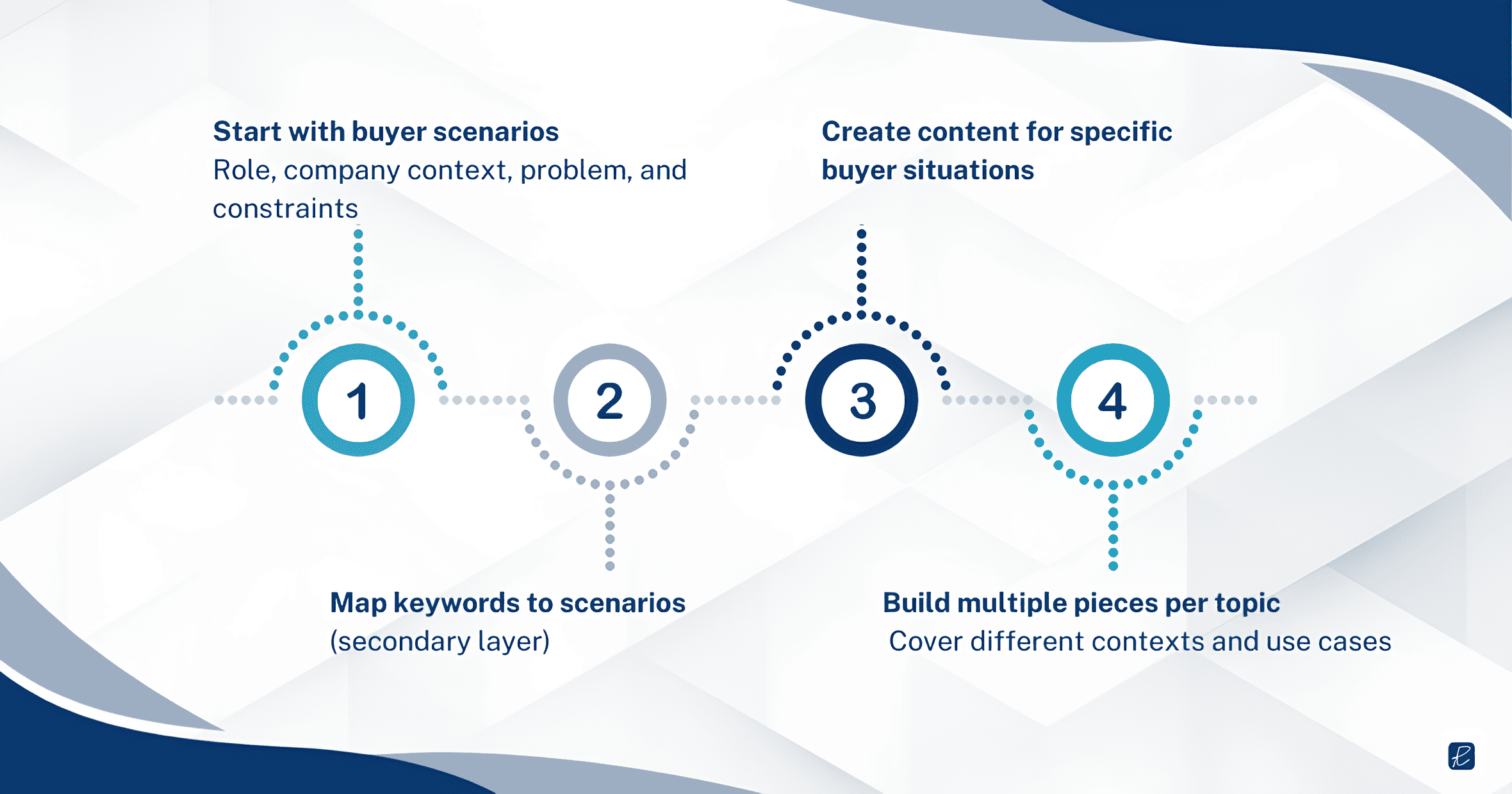
Map buyer scenarios before mapping keywords
The first step is building a scenario map for your ICP. Here, we’re not referring to a persona document (those tend to be demographic sketches with generic pain points). A scenario map captures specific buying situations with enough detail to generate content that LLMs can match to contextual queries.
A useful scenario has four components:
- the buyer’s role
- the company context (size, stage, industry)
- the specific problem or trigger event
- the constraints that shape their options (budget, timeline, internal capabilities, regulatory environment).
“CMO evaluating marketing agencies” is a persona. “CMO at a 150-person B2B SaaS company that just missed its pipeline target for two consecutive quarters and needs to show the board a credible plan for improving inbound without increasing headcount” is a scenario.
The content you produce for that scenario will naturally include the keywords a traditional strategy would target. But it will also include the contextual specificity that makes it a strong candidate for AI citation when someone asks an LLM a question from that exact situation.
Topical depth beats topical breadth for AI citation
One article per topic is the keyword-era model. You identify a keyword, write the definitive article targeting it, and move on to the next keyword. In AI search, this approach has a structural weakness, which is that a single article cannot address the same topic from every buyer context.
The brands that get cited consistently in LLM responses are the ones with topical depth, meaning multiple pieces of content covering the same core topic from different angles, for different buyer situations, at different levels of detail. A brand that has published separate articles on content strategy for early-stage SaaS, content strategy for enterprise B2B, content strategy during a rebrand, and content strategy with no in-house team gives an LLM four different contextual matches for the same broad topic.
The business case for this depth is concrete. Early data supports this. G2’s research found that AI search-driven leads convert 40% better than traditional search leads, because the buyer who arrives via an AI recommendation has already been told the content is relevant to their specific situation. Building contextual coverage is not just a visibility play. It is a qualified traffic play.
This is where GEO (Generative Engine Optimization) diverges most clearly from traditional SEO:
- Traditional SEO rewards consolidation: combine everything into one authoritative page.
- GEO rewards contextual coverage: address the topic from the angles your specific buyers approach it.
Brand positioning becomes a ranking factor
In keyword SEO, brand positioning is a marketing concern, not an SEO concern. You can rank for a keyword without having a clear brand identity, as long as your content matches the query and your domain has authority.
AI search changes this as LLMs do not evaluate your website page by page the way a search engine crawler does. They build a composite understanding of your brand as a single entity, assembled from signals across your entire web presence and third-party sources. When an LLM assembles a response to “What agency should a Series B SaaS company hire for content marketing?”, it draws on its understanding of which brands are associated with B2B, with SaaS, with content marketing, and with early-stage companies. That understanding is built from the accumulated signals across all of a brand’s content, not from a single optimized page.
If your blog covers B2B SaaS topics but your case studies emphasize enterprise clients and your About page describes you as a “full-service digital agency,” you are sending mixed entity signals. An LLM trying to determine whether to recommend you for a SaaS-specific query has conflicting information, and conflicting information usually means you get left out of the response entirely.
Audit your service pages, blog content, case studies, team bios, and structured data to confirm they all tell the same story.
This includes author identity. Google has confirmed that author expertise is a factor in AI Overview source selection, and the same principle applies to how other AI systems assess source credibility. If your blog has no author pages or your authors have no visible professional footprint, you are weakening your content’s citation eligibility.
Your off-site presence shapes your AI entity profile
Brand positioning consistency on your own website is necessary but not sufficient. LLMs build entity profiles from the entire web, not just the pages you control. What industry analysts say about you, how your brand appears in review sites and comparison directories, what customers write about you in forums, and whether your executives are quoted in trade publications all feed into the model’s understanding of what your brand is and who it serves.
G2’s 2025 Buyer Behavior Report found that generative AI chatbots are now the number one source influencing vendor shortlists, ahead of vendor websites, market research firms, and salespeople. Enterprise buyers ranked software review sites and AI search as their top two research sources.
The direct implication is that if your brand is absent or poorly represented on the platforms that AI systems treat as authoritative (review sites, industry publications, analyst coverage), your on-site optimization is working with a handicap.
If those external sources describe your brand inconsistently, or if they don’t mention you at all in the contexts where you want to appear, on-site optimization alone will not close the gap.
Structured data and entity markup are not optional
Structured data has always been an SEO best practice, but its importance for AI search visibility is qualitatively different. In traditional SEO, schema markup helps search engines display rich snippets and understand page content. In AI search, structured data is one of the primary mechanisms LLMs use to build entity associations.
Organization schema with consistent industry, service, and audience attributes tells AI systems what entity you are and what contexts you are relevant to.
FAQ schema packages your expertise in a format that retrieval systems can extract cleanly.
Service schema connecting your offerings to specific industries builds contextual bridges between your brand and the buyer situations where you want to appear.
A caveat, though, is that Google and Bing have confirmed they use structured data in their AI features, but ChatGPT and Perplexity have not publicly confirmed the same for their retrieval pipelines. At least one large-scale study found no direct correlation between schema coverage and AI citation rates. Schema alone does not guarantee citations. What it does is reduce ambiguity about your brand’s identity and topical relevance, which makes it easier for any retrieval system, confirmed or not, to match you to the right queries. The risk of implementing it is near zero. The risk of not implementing it, in a world where your competitors increasingly do, is real.
Format content for information retrieval
Producing the right content for the right buyer scenario is necessary but not sufficient. That content also needs to be formatted in a way that retrieval systems can extract and cite cleanly.
RAG-based AI search works by splitting web content into chunks, matching those chunks to a query, and pulling the best-matching chunks into the model’s response. The formatting of your content determines the quality of those chunks. A page with a clear heading that frames a buyer question, followed by a direct two-to-three sentence answer, followed by supporting evidence and context, produces clean, extractable chunks. A page that buries the answer in the third paragraph after two paragraphs of setup produces chunks that the retrieval system may skip in favor of a competitor’s cleaner format.
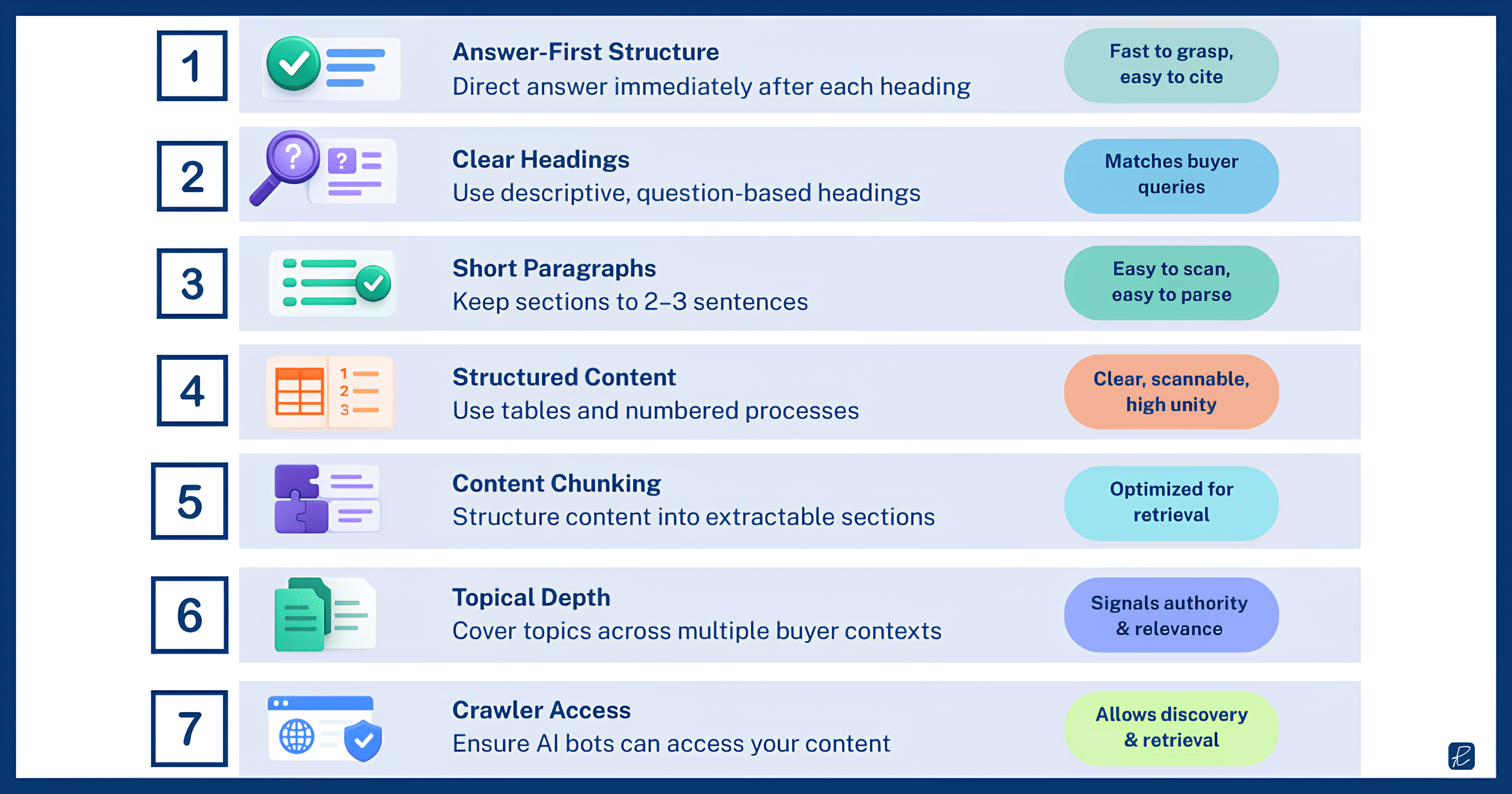
Your content should lead every section with the direct answer to the implicit question the heading raises. Keep paragraphs to two or three sentences so that key claims stand alone without requiring surrounding context. Use descriptive, question-shaped headings rather than vague labels: “How do mid-market SaaS companies approach attribution?” is more retrievable than “Attribution Considerations.” Use tables for any comparative information and numbered lists for any sequential process.
These go beyond aesthetic preferences. They are structural decisions that determine whether your content is extractable by the systems that now mediate a growing share of B2B discovery.
What This Shift Doesn’t Change
Certain fundamentals persist regardless of whether the buyer finds you through Google’s blue links or an LLM-generated response.
Content quality now has a harder floor. In traditional search, mediocre content could survive on page two through backlinks and technical optimization. In AI search, the selection mechanism is different. The LLM chooses the best available answer from its retrieval set, not the best-optimized page. If your content is generic and a competitor’s is specific, the competitor gets cited regardless of domain authority.
Yext’s analysis of 6.8 million AI citations found that 86% came from brand-managed sources, which means the quality of your own content is the primary determinant of whether you appear in AI responses, not third-party backlinks.
Technical SEO hygiene, including crawlability, page speed, mobile usability, and clean URL structures, still determines whether your content gets indexed in the first place. An LLM cannot cite a page it has never encountered, and the pipeline that feeds content into AI training data and retrieval systems still begins with web crawlers.
One technical detail that traditional SEO teams rarely consider has become a prerequisite for AI visibility is crawler access policies. AI platforms use dedicated crawlers that are separate from Googlebot and Bingbot. Many B2B sites inadvertently block these crawlers through overly broad robots.txt rules, or their security teams have blocked AI bots as a precaution without understanding the visibility cost. If GPTBot is blocked on your site, your content will not appear in ChatGPT search responses regardless of how well-structured or contextually relevant it is. Audit your robots.txt for AI crawler access as a first step, before investing in content restructuring or schema implementation.
And the basic principle of writing content that answers real buyer questions has always been the core of effective content marketing. The shift to AI search does not invent that principle. It just punishes brands that have been getting away with ignoring it.

















